Deploying Qwen2.5-Coder with Llama.cpp and UV
Running large language models locally has traditionally been challenging, requiring significant hardware resources and technical expertise. In this guide, we'll walk through deploying Qwen2.5-Coder, a powerful 32GB AI coding assistant, using llama.cpp and modern tooling to run efficiently on consumer hardware.
Do you want to learn Enterprise AI Operations with AWS?
Master enterprise AI operations with AWS services
Check out our course!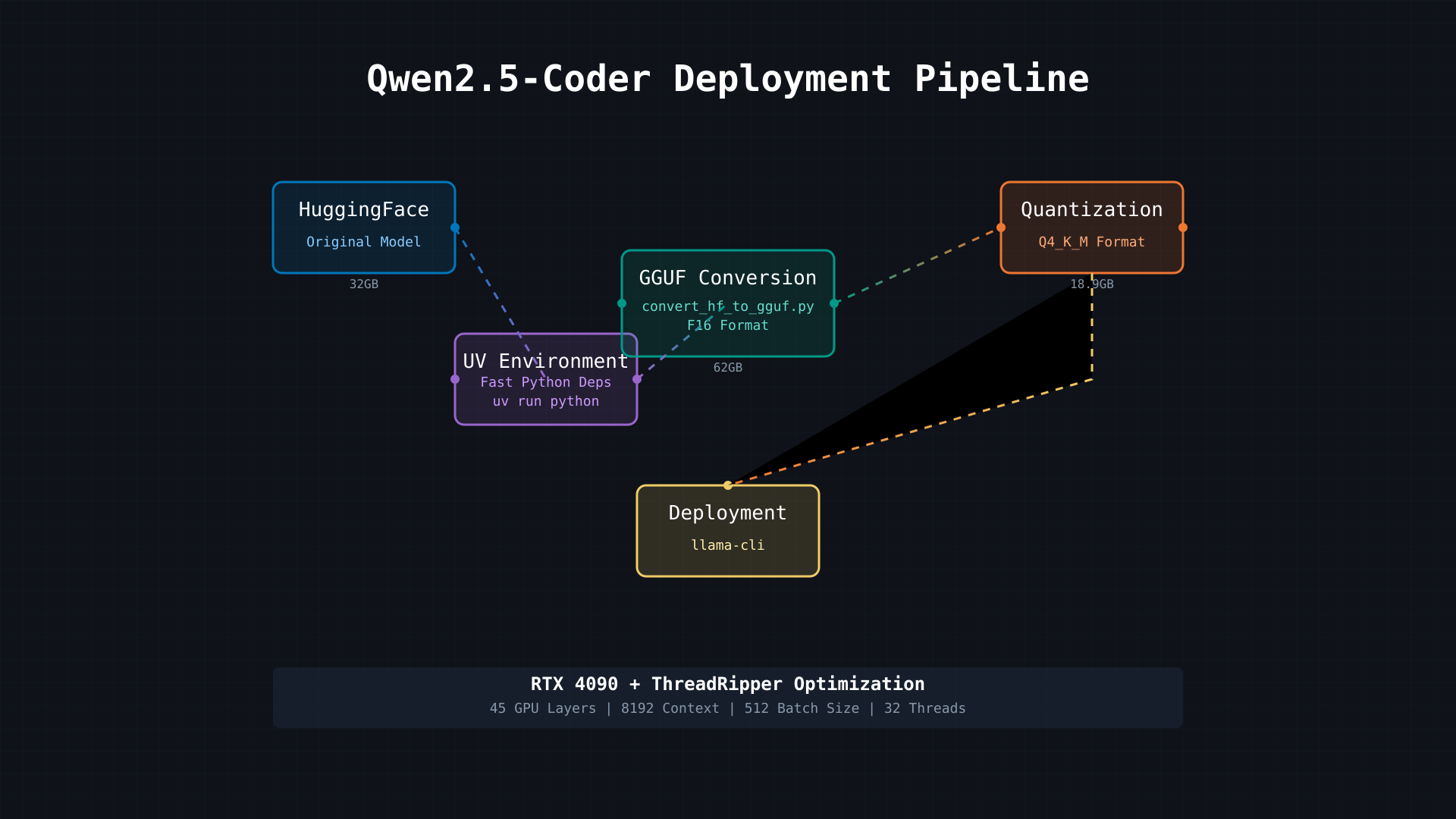
Understanding the Pipeline
The deployment process involves several key stages, each optimizing the model in different ways. Let's break down each component and understand its role in getting Qwen2.5-Coder running on consumer hardware.
Stage 1: Model Download from HuggingFace
HuggingFace serves as our starting point - think of it as GitHub for AI models. Qwen2.5-Coder begins as a 32GB model, downloaded using the huggingface-cli tool. This original format is optimized for training rather than deployment, which is why we need subsequent optimization steps.
Stage 2: The UV Environment
One of the most innovative aspects of our pipeline is the use of UV, a modern Python package manager that dramatically improves the setup process. Key benefits include:
- Lightning-fast dependency resolution: UV handles Python packages in seconds rather than minutes
- Isolated environments: Prevents conflicts between Python packages
- Consistent execution: The
uv run pythoncommand ensures reproducible environments
Stage 3: GGUF Conversion
The conversion stage transforms the model into a universal format optimized for deployment:
uv run python convert_hf_to_gguf.py /path/to/model \
--outfile qwen2.5-coder-32b.gguf \
--outtype f16 \
--use-temp-file \
--verbose
This stage temporarily increases the model size to 62GB but prepares it for efficient quantization.
Stage 4: Quantization
Quantization is where the magic happens in terms of size optimization:
./llama-quantize qwen2.5-coder-32b.gguf \
qwen2.5-coder-32b-q4_k_m.gguf q4_k_m
This process:
- Reduces model size from 62GB to 18.9GB
- Maintains approximately 98% of original performance
- Optimizes for consumer GPU memory constraints
Stage 5: Deployment Configuration
The final deployment uses llama-cli with carefully tuned parameters:
./llama-cli -m qwen2.5-coder-32b-q4_k_m.gguf \
--n-gpu-layers 45 \
--ctx-size 8192 \
--batch-size 512 \
--threads 32 \
--temp 0.7 \
--repeat-penalty 1.1 \
--rope-freq-base 10000 \
--rope-freq-scale 0.5 \
--mlock \
--numa distribute \
--flash-attn \
-cnv
Key Benefits
- Efficient Resource Usage: Runs a 32GB model on a 24GB RTX 4090
- Optimized Performance: Balances CPU and GPU workloads across 45 GPU layers
- Practical Deployment: Makes enterprise-grade AI accessible on consumer hardware
Hardware Optimization
The pipeline is specifically optimized for:
- NVIDIA RTX 4090 (24GB VRAM)
- ThreadRipper CPU (48 threads)
- High-speed storage for model loading
Performance Tuning Tips
- Monitor VRAM usage with
nvidia-smi - Adjust GPU layers based on available memory
- Balance thread count with CPU cores
- Use
mlockto prevent memory swapping - Enable
numa distributefor ThreadRipper optimization
Common Challenges and Solutions
Memory Management
- Start with 45 GPU layers and adjust based on VRAM usage
- Monitor system RAM for model loading overhead
- Use thread settings that match your CPU architecture
Performance Optimization
- Enable Flash Attention when available
- Tune batch size for your specific workload
- Adjust context size based on your use case
Conclusion
This deployment pipeline demonstrates how modern tools like UV, llama.cpp, and careful optimization can make powerful AI models run efficiently on consumer hardware. The combination of quantization techniques, hardware-aware configuration, and proper resource management transforms a research-grade model into a practical tool for everyday use.
Remember to monitor system resources during deployment and adjust parameters based on your specific hardware configuration and use case requirements.
Recommended Courses
Based on this article's content, here are some courses that might interest you:
-
Enterprise AI Operations with AWS (2 weeks)
Master enterprise AI operations with AWS services -
AWS Advanced AI Engineering (1 week)
Production LLM architecture patterns using Rust, AWS, and Bedrock. -
Natural Language AI with Bedrock (1 week)
Get started with Natural Language Processing using Amazon Bedrock in this introductory course focused on building basic NLP applications. Learn the fundamentals of text processing pipelines and how to leverage Bedrock's core features while following AWS best practices. -
Generative AI with AWS (4 weeks)
This GenAI course will guide you through everything you need to know to use generative AI on AWSn introduction on using Generative AI with AWS -
Building AI Applications with Amazon Bedrock (4 weeks)
Learn Building AI Applications with Amazon Bedrock
Learn more at Pragmatic AI Labs