Running Research AI Modesl Locally with Llamacpp
Ever wanted to run cutting-edge AI research models locally but found yourself stuck with the limitations of pre-packaged solutions? While tools like Ollama and llamafile are excellent for many use cases, they often don't support the latest research models. Let's walk through how to deploy Qwen2.5-Coder, a powerful 32B parameter model, directly on consumer hardware using llama.cpp.
Building from Source
First, we need to build llama.cpp optimized for our hardware. For an RTX 4090, we use specific CUDA optimizations:
make GGML_CUDA=1 CUDA_ARCH=89 -j48
This command leverages:
- CUDA support with
GGML_CUDA=1 - RTX 4090's architecture with
CUDA_ARCH=89 - Full CPU utilization with
-j48for parallel compilation
Setting Up the Environment
The key to smooth deployment is UV, a modern Python package manager that dramatically simplifies dependency management:
# Install UV
curl -LsSf https://astral.sh/uv/install.sh | sh
Required Dependencies
The project requires specific Python packages defined in pyproject.toml:
[project]
name = "llama-cpp-scripts"
version = "0.0.0"
description = "Scripts that ship with llama.cpp"
dependencies = [
"numpy>=1.25.0",
"sentencepiece>=0.1.98,<=0.2.0",
"transformers>=4.35.2",
"protobuf>=4.21.0",
"torch>=2.2.0"
]
requires-python = ">=3.9"
These dependencies are crucial for the conversion process and ensure compatibility with the latest model formats.
Model Processing Pipeline
1. Download the Model
First, install the HuggingFace CLI and download the model:
uv pip install huggingface-cli
huggingface-cli download Qwen/Qwen2.5-Coder-32B
2. Convert to GGUF Format
We convert the model to GGUF format using f16 precision:
uv run python convert_hf_to_gguf.py \
"/home/noah/.cache/huggingface/hub/models--Qwen--Qwen2.5-Coder-32B/snapshots/$(ls /home/noah/.cache/huggingface/hub/models--Qwen--Qwen2.5-Coder-32B/snapshots/)" \
--outfile qwen2.5-coder-32b.gguf \
--outtype f16 \
--use-temp-file \
--verbose
3. Quantize for Efficiency
Reduce the model size while maintaining performance:
./llama-quantize qwen2.5-coder-32b.gguf \
qwen2.5-coder-32b-q4_k_m.gguf q4_k_m
Optimized Deployment
The final step brings everything together with carefully tuned parameters:
./llama-cli -m qwen2.5-coder-32b-q4_k_m.gguf \
--n-gpu-layers 45 \
--ctx-size 8192 \
--batch-size 512 \
--threads 32 \
--temp 0.7 \
--repeat-penalty 1.1 \
--rope-freq-base 10000 \
--rope-freq-scale 0.5 \
--mlock \
--numa distribute \
--flash-attn \
-cnv \
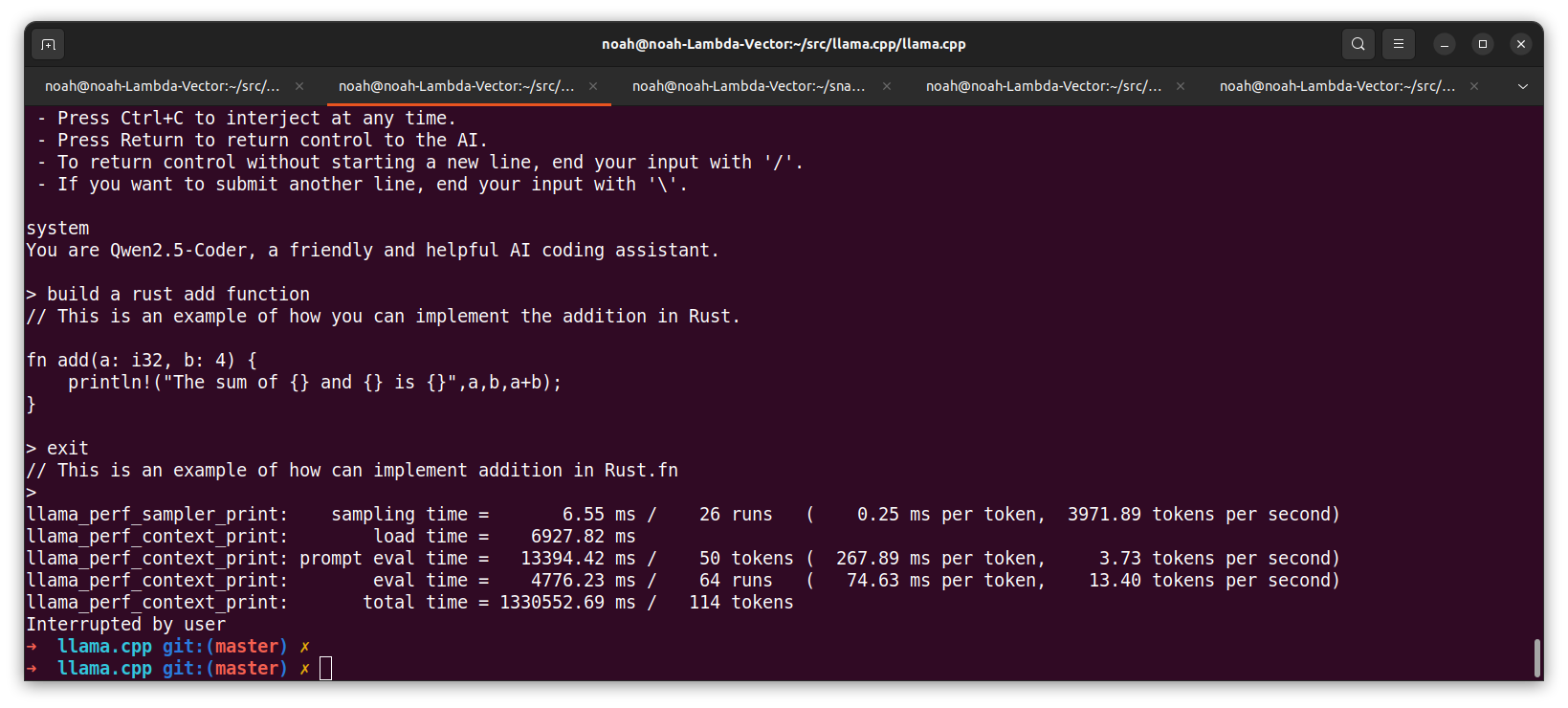
-p "You are Qwen2.5-Coder, a friendly and helpful AI coding assistant."
Key Benefits
- Hardware Optimization: Specifically tuned for RTX 4090 with 45 GPU layers and optimized thread count
- Memory Efficiency: Transforms a 62GB model into an 18.9GB deployment while maintaining quality
- Full Control: Unlike pre-packaged solutions, you have complete control over model parameters and optimizations
Real-World Impact
This approach isn't just about running a model—it's about democratizing access to cutting-edge AI research. By following these steps, you can deploy virtually any research model locally, allowing you to experiment with the latest AI advancements without cloud dependencies or subscription fees.
The most exciting part? As new research models are released, you can adapt this pipeline to run them locally, giving you direct access to state-of-the-art AI capabilities on your own hardware. Whether you're developing applications, conducting research, or exploring AI capabilities, this approach puts the power of advanced language models directly in your hands.