Chapter 6: Serverless ETL Technologies #
Serverless technology is exciting because it doesn’t exist without Cloud computing. The Cloud-Native terms arise because they are a “native” capability of the distributed, elastic compute environment provided. The word serverless means that servers are not top of mind in solving problems. If you like to solve problems quickly, as I do, then you will love serverless. A thought turns into code, which turns into a solution.
One way to get started with the examples in this chapter is to watch the following screencast serverless cookbook with AWS and GCP. The source code is in the Github Repo https://github.com/noahgift/serverless-cookbook.
Video Link: https://www.youtube.com/watch?v=SpaXekiDpFA
AWS Lambda #
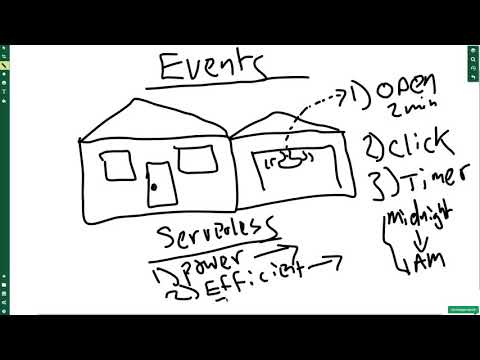
AWS Lambda is a building block for many things on AWS. It is a great place to start when diving into serverless technology. First, let’s dive into what occurs under the hood when you use AWS Lambda, as shown in the diagram. A house with a lightbulb in the garage can turn on many ways, the light switch, or the garage door open event. A Lambda responds to many signals as well.

Learn how to AWS Lambda as a Garage Lightbulb in the following screencast.

Video Link: https://www.youtube.com/watch?v=nNKYwxf96bk
An excellent way to get started with a first Lambda function is via a simple example. Learn how to build a Marco Polo Lambda function in the following screencast.

Video Link: https://www.youtube.com/watch?v=AlRUeNFuObk
You can find the code for the example below. gist for Marco
def lambda_handler(event, context):
if event["name"] == "Marco":
return "Polo"
Invoking AWS Lambda from the CLI #
A convenient trick is to use an AWS Cloud Shell or AWS Cloud9 environment to invoke an AWS Lambda. How could you do this?
aws lambda invoke --function-name MarcoPolo9000 --payload '{"name": "Marco" }' out.txt | less out.txt
The real example is in Github here.
AWS Step Functions #
Note you could also chain many of these functions together using AWS Step Functions. You can see an example of the workflow of a chain of Lambda functions in the diagram.

Here is the code for the example.
def lambda_handler(event, context):
if event["name"] == "Polo":
return "Marco"
Notice how each function emits an output than then goes to the next operation. The following code example is in Github.
{
"Comment": "This is Marco Polo",
"StartAt": "Marco",
"States": {
"Marco": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:561744971673:function:marco20",
"Next": "Polo"
},
"Polo": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:561744971673:function:polo",
"Next": "Finish"
},
"Finish": {
"Type": "Pass",
"Result": "Finished",
"End": true
}
}
}
You can watch a Marco Polo Step function in the following screencast.
Video Link: https://www.youtube.com/watch?v=neOF0sxmYjY
Another excellent reference is the Web Scraping Pipeline Github Project
Developing AWS Lambda Functions with AWS Cloud9 #
Cloud9 has many capabilities built in the make developing with AWS Lambda easier. These include debugging, importing remote lambda functions, and a wizard.
Learn how to Develop AWS Lambda functions with AWS Cloud9 in the following screencast.

Video Link: https://www.youtube.com/watch?v=QlIPPNxd7po
Building an API #
The following code creates an API via API Gateway.
Python Lambda API Gateway Example
import json
import decimal
def lambda_handler(event, context):
print(event)
if 'body' in event:
event = json.loads(event["body"])
amount = float(event["amount"])
res = []
coins = [1,5,10,25]
coin_lookup = {25: "quarters", 10: "dimes", 5: "nickels", 1: "pennies"}
coin = coins.pop()
num, rem = divmod(int(amount*100), coin)
res.append({num:coin_lookup[coin]})
while rem > 0:
coin = coins.pop()
num, rem = divmod(rem, coin)
if num:
if coin in coin_lookup:
res.append({num:coin_lookup[coin]})
response = {
"statusCode": "200",
"headers": { "Content-type": "application/json" },
"body": json.dumps({"res": res})
}
return response
Building a serverless data engineering pipeline #
One strong use case for AWS Lambda is to build serverless data engineering pipelines.
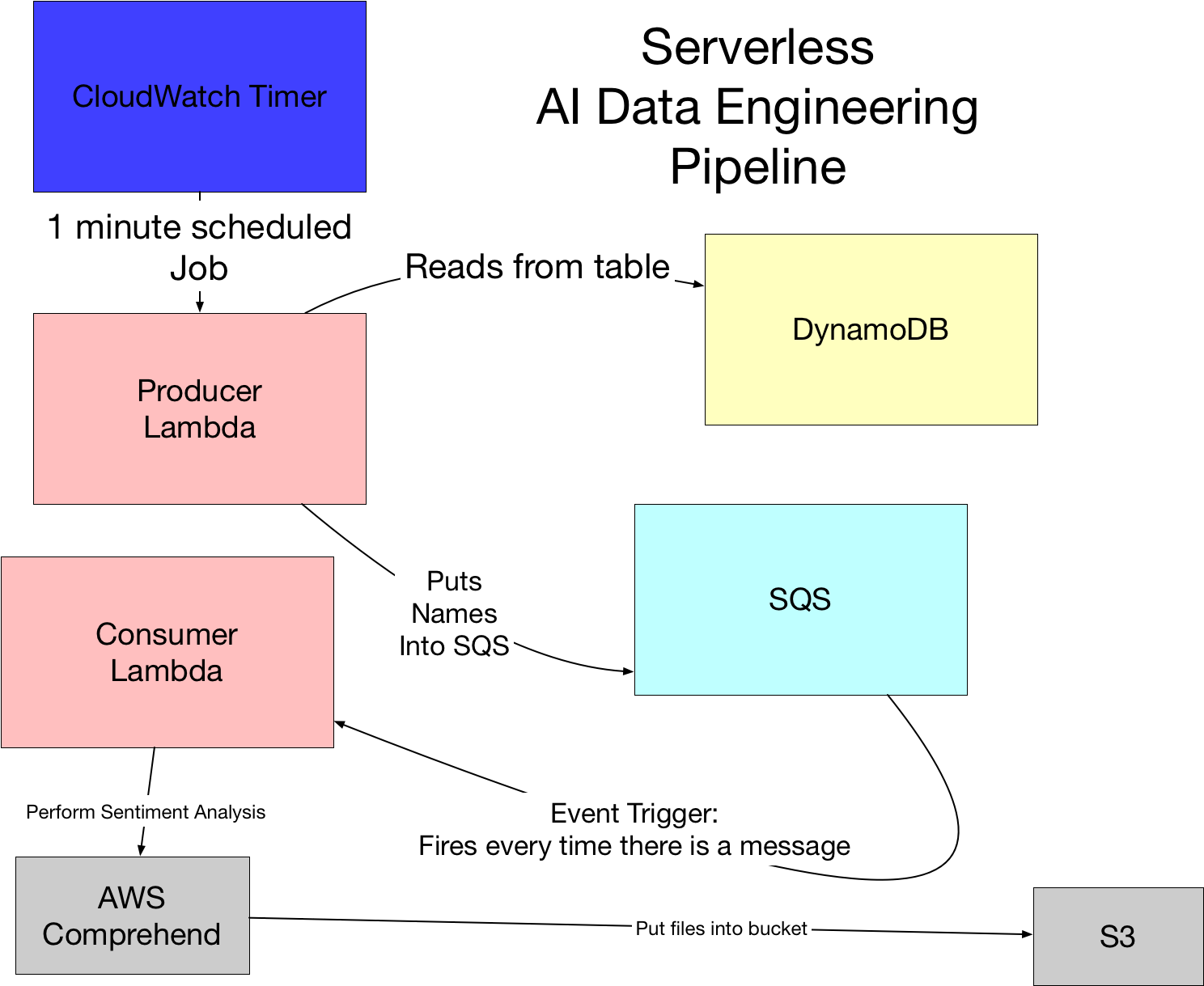
Learn how to Build a Serverless Data Engineering Pipeline in the following screencast.

Video Link: https://www.youtube.com/watch?v=zXxdbtamoa4
- You can use this reference Github Project for AWS Lambda
Computer Vision on an AWS S3 Bucket with AWS Lambda #
Another handy feature of AWS Lambda is running code in response to objects placed in Amazon S3, like an image. In this example, the AWS Computer Vision API detects the labels on any image in the bucket.
import boto3
from urllib.parse import unquote_plus
def label_function(bucket, name):
"""This takes an S3 bucket and a image name!"""
print(f"This is the bucketname {bucket} !")
print(f"This is the imagename {name} !")
rekognition = boto3.client("rekognition")
response = rekognition.detect_labels(
Image={"S3Object": {"Bucket": bucket, "Name": name,}},
)
labels = response["Labels"]
print(f"I found these labels {labels}")
return labels
def lambda_handler(event, context):
"""This is a computer vision lambda handler"""
print(f"This is my S3 event {event}")
for record in event['Records']:
bucket = record['s3']['bucket']['name']
print(f"This is my bucket {bucket}")
key = unquote_plus(record['s3']['object']['key'])
print(f"This is my key {key}")
my_labels = label_function(bucket=bucket,
name=key)
return my_labels
Exercise-AWS Lambda-Step Functions #
-
Topic: Build a step function pipeline
-
Estimated time: 20 minutes
-
People: Individual or Final Project Team
-
Slack Channel: #noisy-exercise-chatter
-
Directions (Do one or both):
- Basic Version: Create an AWS Lambda function that takes an input and run it inside of a Step Function
- Advanced Version: Create an AWS Lambda function that takes an input and runs it inside a Step Function, then sends the output to another AWS Lambda. See the Marco Polo Step Function above.
- Share screenshot + gist in slack.
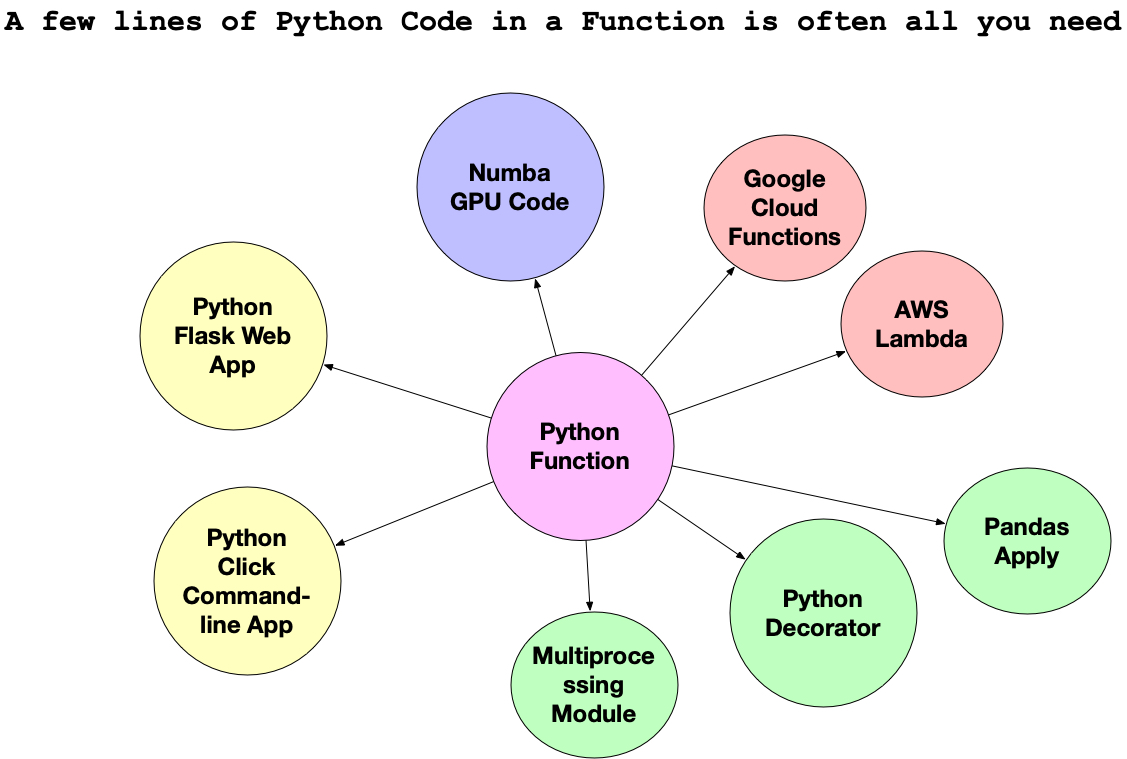
Faas (Function as a Service) #
The function is the center of the universe with cloud computing. In practice, this means anything that is a function could map into a technology that solves a problem: containers, Kubernetes, GPUs, and more.
Chalice Framework on AWS Lambda #
Another option for developing serverless AWS applications is to use the chalice framework. Here is how to get started.
A. Create credentials.
$ mkdir ~/.aws
$ cat >> ~/.aws/config
[default]
aws_access_key_id=YOUR_ACCESS_KEY_HERE
aws_secret_access_key=YOUR_SECRET_ACCESS_KEY
region=YOUR_REGION (such as us-west-2, us-west-1, etc)
B. Next, setup a project.
python3 -m venv ~/.hello && source ~/.hello/bin/activate
chalice new-project hello && hello
Inspect the app.py file.
from chalice import Chalice
app = Chalice(app_name='hello')
@app.route('/')
def index():
return {'hello': 'world'}
C. Then run local
(.chalicedemo) ec2-user:~/environment/helloworld4000 $ chalice local
Serving on http://127.0.0.1:8000
Notice that this framework can do advanced tricks. It can also run timed lambdas.
from chalice import Chalice, Rate
app = Chalice(app_name="helloworld")
# Automatically runs every 5 minutes
@app.schedule(Rate(5, unit=Rate.MINUTES))
def periodic_task(event):
return {"hello": "world"}
It can also run event-driven lambdas.
from chalice import Chalice
app = Chalice(app_name="helloworld")
# Whenever an object uploads to 'mybucket'
# this lambda function will be invoked.
@app.on_s3_event(bucket='mybucket')
def handler(event):
print("Object uploaded for bucket: %s, key: %s"
% (event.bucket, event.key))
Google Cloud Functions #
Google Cloud Functions have much in common with AWS Lambda. They work by invoking a function in response to an event. You can view a screencast of this workflow here.
You can watch Google Cloud functions in the following screencast.
Video Link: https://www.youtube.com/watch?v=SqxdFykehRs
Why would you use Cloud Functions on GCP? According to the official docs, the use cases include ETL, Webhooks, APIs, Mobile Backends, and IoT.

The editor allows you to add “packages” on the fly.

import wikipedia
def hello_wikipedia(request):
"""Takes JSON Payload {"entity": "google"}
"""
request_json = request.get_json()
if request_json and 'entity' in request_json:
entity = request_json['entity']
print(entity)
res = wikipedia.summary(entity, sentences=1)
return res
else:
return f'No Payload'
Once the Google Cloud Function deploys, it runs in the console.

The logs show up in the GCP platform. There is where print statements show up.

Notice that the GCP Console can also invoke this same function. First, let’s describe it and make sure it deploys.
gcloud functions describe function-2

Next, we can invoke it from the terminal, which is very powerful for a Data Science-based workflow.
gcloud functions call function-2 --data '{"entity":"google"}'
The results are here.

Now, let’s try a new company, this time Facebook.
gcloud functions call function-2 --data '{"entity":"facebook"}'
The output shows the following.
executionId: 6ttk1pjc1q14
result: Facebook is an American online social media and social networking service
based in Menlo Park, California and a flagship service of the namesake company Facebook,
Inc.
Can we go further and call an AI API? Yes, we can. First, add this library to the requirements.txt
# Function dependencies, for example:
# package>=version
google-cloud-translate
wikipedia
Next, run this function.
import wikipedia
from google.cloud import translate
def sample_translate_text(text="YOUR_TEXT_TO_TRANSLATE", project_id="YOUR_PROJECT_ID"):
"""Translating Text."""
client = translate.TranslationServiceClient()
parent = client.location_path(project_id, "global")
# Detail on supported types can be found here:
# https://cloud.google.com/translate/docs/supported-formats
response = client.translate_text(
parent=parent,
contents=[text],
mime_type="text/plain", # mime types: text/plain, text/html
source_language_code="en-US",
target_language_code="fr",
)
# Display the translation for each input text provided
for translation in response.translations:
print(u"Translated text: {}".format(translation.translated_text))
return u"Translated text: {}".format(translation.translated_text)
def translate_test(request):
"""Takes JSON Payload {"entity": "google"}
"""
request_json = request.get_json()
if request_json and 'entity' in request_json:
entity = request_json['entity']
print(entity)
res = wikipedia.summary(entity, sentences=1)
trans=sample_translate_text(text=res, project_id="cloudai-194723")
return trans
else:
return f'No Payload'

Can you expand this even further to accept a payload that allows any language from the list of languages GCP supports here? Here is a gist of this code.
import wikipedia
from google.cloud import translate
def sample_translate_text(text="YOUR_TEXT_TO_TRANSLATE",
project_id="YOUR_PROJECT_ID", language="fr"):
"""Translating Text."""
client = translate.TranslationServiceClient()
parent = client.location_path(project_id, "global")
# Detail on supported types can be found here:
# https://cloud.google.com/translate/docs/supported-formats
response = client.translate_text(
parent=parent,
contents=[text],
mime_type="text/plain", # mime types: text/plain, text/html
source_language_code="en-US",
target_language_code=language,
)
# Display the translation for each input text provided
for translation in response.translations:
print(u"Translated text: {}".format(translation.translated_text))
return u"Translated text: {}".format(translation.translated_text)
def translate_test(request):
"""Takes JSON Payload {"entity": "google"}
"""
request_json = request.get_json()
print(f"This is my payload {request_json}")
if request_json and 'entity' in request_json:
entity = request_json['entity']
language = request_json['language']
print(f"This is the entity {entity}")
print(f"This is the language {language}")
res = wikipedia.summary(entity, sentences=1)
trans=sample_translate_text(text=res,
project_id="cloudai-194723", language=language)
return trans
else:
return f'No Payload'
The main takeaway in this change is grabbing another value from the request_json payload. In this case, language. The trigger accepts a new payload with the language added.
{"entity": "google", "language": "af"}

Another item to mention is that you also may want to use the curl command to test out your cloud function. Here is an example of a curl command that you could tweak.
curl --header "Content-Type: application/json" --request POST --data '{"entity":"google"}' https://us-central1-<yourproject>.
cloudfunctions.net/<yourfunction>
Reference GCP Qwiklabs #
Additional Qwiklabs can be helpful to continue to study Google Cloud Functions.
Azure Flask Machine Learning Serverless #
Could you do more than just run functions? Sure, in this example Github Repository, you can see how to Deploy a Flask Machine Learning Application on Azure App Services using Continuous Delivery.

To run it locally, follow these steps #
- Create a virtual environment and source
python3 -m venv ~/.flask-ml-azure
source ~/.flask-ml-azure/bin/activate
-
Run
make install -
Run
python app.py -
In a separate shell run:
./make_prediction.sh
Here is what a successful prediction looks like in action.
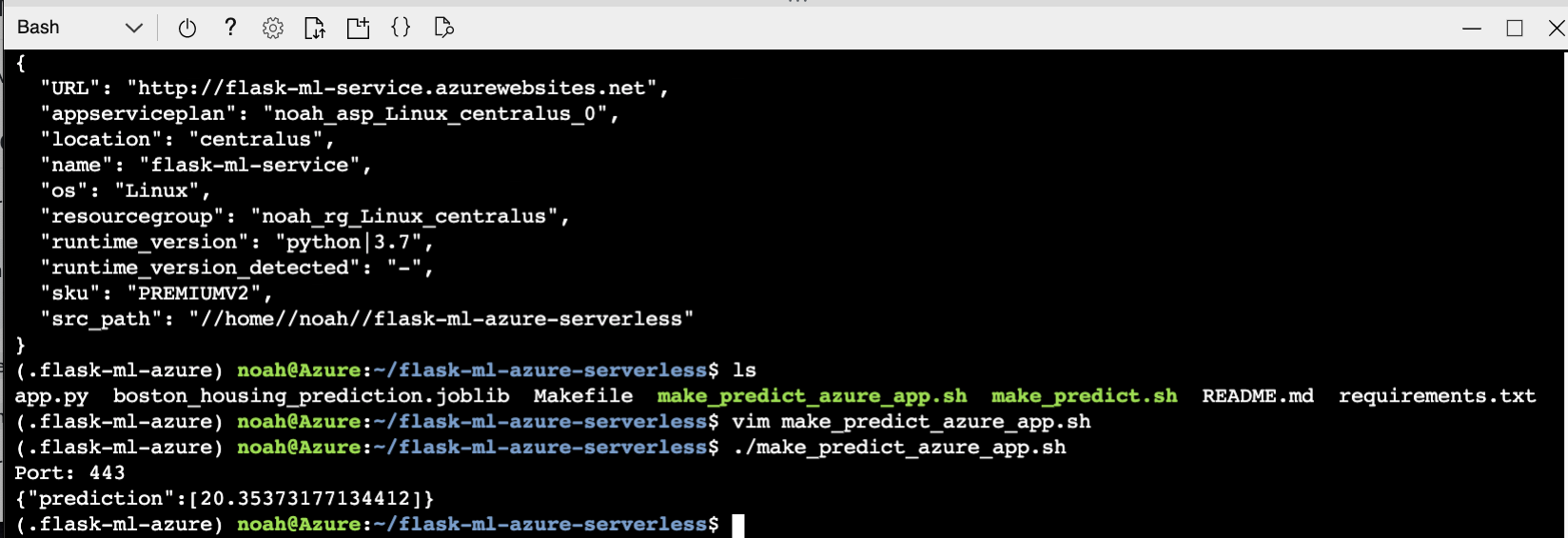
You can watch this Azure Flask Serverless Deploy in the following screencast.

Video Link: https://www.youtube.com/watch?v=3KF9DltYvZU
Cloud ETL #
The cloud takes complex problems that could be currently solved by a team of 50 people and allows it to be a button click. In the “real world,” you have to automate the data pipeline via the ETL (Extract, Transfer, Load) process. The diagram below shows how AWS S3 is the central repo for the data.

Next, AWS Glue indexes the cloud storage bucket and creates a database that can be used by AWS Athena. What is unique about this?
- Almost no code (only a little SQL to query)
- Serverless
- Automatable
Here is a screencast of AWS Glue and AWS Athena working together to catalog data and search it at scale:
You can watch AWS Glue work in the following screencast.
Video Link: https://www.youtube.com/watch?v=vqubkjfvx0Q)
Real-World Problems with ETL Building a Social Network From Scratch #
In my time in the Bay Area, I was the CTO of a Sports Social network, and I built a Social Network from Zero. There are a few big problems that crop up.
Cold-Start Problem #
How do you bootstrap a social network and get users?

Building Social Network Machine Learning Pipeline From Scratch #
How can you predict the impact on the platform from social media signals?

Results of ML Prediction Pipeline:




Case Study-How-do-you-construct-a-News-Feed? #
- How many users should someone follow?
- What should be in the feed?
- What algorithm do you use to generate the feed?
- Could you get a Feed to be an O(1) lookup? Hint…pre-generate feed.
- What if one user posts 1000 items a day, but you follow 20 users, and the feed paginates at 25 results?
Summary #
This chapter covers an essential technology in the Cloud, serverless. All major cloud platforms have serverless technology, and it worth mastering these techniques.